14 ژوئن 2023 -توسط مگی لیندنبرگ، دانشگاه پیتسبورگ
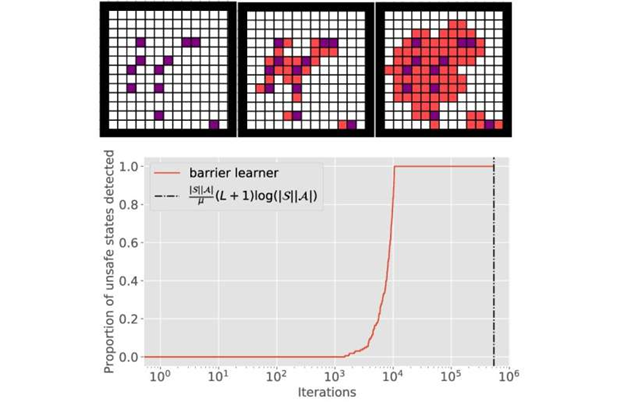
نوردهی نهایی نرمال شده برای μ = 0.1 به عنوان تابعی از، برای سطح تحمل متغیر α. مقادیر بزرگتر α و دستیابی به نقص کمتر (که به معنای تشخیص سریعتر است). اعتبار: IEEE Transactions on Automatic Control (2023
کودکانی که در ابتدا راه رفتن را یاد می گیرند ممکن است کمی تند بروند و به زمین بیفتند یا به یک وسیله راه بروند. با این حال، آن عنصر علت و معلولی به آنها اطلاعات ارزشمندی در مورد نحوه حرکت بدنشان در فضا می آموزد تا بتوانند در آینده از سقوط اجتناب کنند.
ماشینها به روشهای مشابهی که انسانها انجام میدهند، یاد میگیرند، از جمله یادگیری از اشتباهاتشان. با این حال، برای بسیاری از ماشینها – مانند ماشینهای خودران و سیستمهای برق – یادگیری در حین کار با در خطر بودن ایمنی انسان مشکلساز است. همانطور که یادگیری ماشین بالغ و تکثیر می شود، علاقه فزاینده ای به استفاده از آن در سیستم های مستقل بسیار پیچیده و حیاتی وجود دارد. با این حال، خطرات ایمنی ذاتی در فرآیند آموزش و فراتر از آن مانع از نوید این فناوریها میشود.
یک مقاله تحقیقاتی جدید این ایده را به چالش می کشد که برای یادگیری اقدامات ایمن در محیط های ناآشنا به تعداد نامحدودی آزمایش نیاز دارید. این مقاله که اخیراً در ژورنال IEEE Transactions on Automatic Control منتشر شده است، رویکرد جدیدی را ارائه می دهد که یادگیری اقدامات ایمن را با اطمینان کامل تضمین می کند، در حالی که تعادل بین بهینه بودن، مواجهه با موقعیت های خطرناک و تشخیص سریع اقدامات ناامن را مدیریت می کند.
خوان آندرس بازرک، استادیار مهندسی برق و کامپیوتر در سوانسون دانشکده مهندسی، که همراه با دانشیار انریکه مالادا در دانشگاه جان هاپکینز، این تحقیق را رهبری کرد. توضیح داد: “به طور کلی، یادگیری ماشین به دنبال بهینه ترین راه حل است که می تواند منجر به خطاهای بیشتری در طول مسیر شود. این مشکل زمانی است که خطا ممکن است به معنای برخورد با دیوار باشد.”
در این مطالعه نشان میدهیم که یادگیری سیاستهای ایمن با یادگیری سیاستهای بهینه تفاوت اساسی دارد و میتوان آن را بهصورت جداگانه و کارآمد انجام داد».
تیم تحقیقاتی مطالعاتی را در دو سناریو مختلف برای نشان دادن مفهوم خود انجام دادند. آنها با ایجاد فرضیات معقول در مورد اکتشاف، الگوریتمی ایجاد کردند که تمام اقدامات ناامن را در تعداد محدودی دور تشخیص می دهد. این تیم همچنین با چالش یافتن سیاستهای بهینه برای فرآیند تصمیمگیری مارکوف (MDP) با محدودیتهای تقریباً مطمئن مقابله کرد.
تجزیه و تحلیل آنها بر یک معاوضه بین زمان لازم برای شناسایی اقدامات ناایمن در MDP اساسی و سطح قرار گرفتن در معرض رویدادهای ناایمن تأکید کرد. MDP مفید است زیرا چارچوبی ریاضی برای مدلسازی تصمیمگیری در موقعیتهایی که نتایج تا حدی تصادفی و تا حدودی تحت کنترل یک تصمیمگیر هستند، فراهم میکند.
برای تایید یافته های نظری خود، محققان شبیه سازی هایی را انجام دادند که مبادلات شناسایی شده را تایید کرد. این یافته ها همچنین نشان می دهد که گنجاندن محدودیت های ایمنی می تواند روند یادگیری را تسریع کند.
بازرک اظهار داشت: این تحقیق این باور رایج را که یادگیری اقدامات ایمن مستلزم تعداد نامحدودی آزمایش است به چالش می کشد. “نتایج ما نشان می دهد که با مدیریت موثر معاوضه بین بهینه، قرار گرفتن در معرض رویدادهای ناامن و زمان تشخیص، می توانیم به ایمنی تضمین شده بدون تعداد بی نهایت اکتشاف دست یابیم. این پیامدهای قابل توجهی برای روباتیک، سیستم های خودمختار، و هوش مصنوعی و غیره دارد.