11 ژانویه 2024 – توسط دانشگاه خودمختار بارسلون
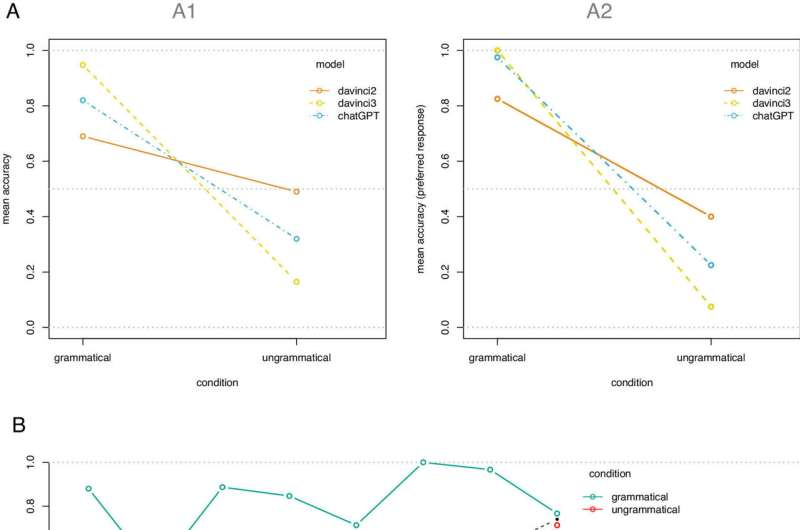
(الف) دقت متوسط بر اساس شرایط و مدل: (A1) پاسخ های فردی. (A2) پاسخ های ترجیحی در هر جمله. (ب) دقت میانگین بر اساس پدیده و شرایط. خط چین سیاه نشان دهنده دقت متوسط برای هر پدیده در هر دو شرایط است. اعتبار: مجموعه مقالات آکادمی ملی علوم (2023). DOI:
مطالعه محققان UAB و URV که در PNAS منتشر شده است نشان می دهد که انسان اشتباهات گرامری را در جمله تشخیص می دهد در حالی که هوش مصنوعی این کار را نمی کند. محققان مهارت های انسان ها و سه مورد از بهترین مدل زبان بزرگ موجود در حال حاضر را مقایسه کرده اند.
زبان یکی از اصلی ترین ویژگی هایی است که انسان را از سایر گونه ها متمایز می کند. از کجا می آید، چگونه آموخته می شود و چرا مردم توانسته اند چنین سیستم ارتباطی پیچیده ای را ایجاد کنند، سؤالات بسیاری را برای زبان شناسان و پژوهشگران حوزه های مختلف تحقیقاتی ایجاد کرده است.
در سالهای اخیر، پیشرفت قابلتوجهی در تلاش برای آموزش زبان رایانهها صورت گرفته است و این منجر به ظهور مدلهای زبانی به اصطلاح بزرگ شده است، فناوریهایی که با حجم عظیمی از دادهها آموزش دیدهاند که اساس برخی از برنامههای کاربردی هوش مصنوعی (AI) هستند. : به عنوان مثال، موتورهای جستجو، مترجمان ماشینی یا مبدل های صوتی به متن.
اما این مدل ها چه مهارت های زبانی دارند؟ آیا می توان آنها را با یک انسان مقایسه کرد؟ یک تیم تحقیقاتی به رهبری URV با مشارکت Humboldt-Universitat de Berlin، Universitat Autònoma de Barcelona (UAB) و موسسه تحقیقات و مطالعات پیشرفته کاتالان (ICREA) این سیستم ها را آزمایش کردند تا بررسی کنند که آیا مهارت های زبانی آنها قابل مقایسه است یا خیر. افراد برای انجام این کار، آنها مهارتهای انسانها را با سه مدل زبان بزرگ در حال حاضر مقایسه کردند: دو مدل مبتنی بر GPT3 و یکی (ChatGPT) بر اساس GP3.5.
به آنها وظیفه ای داده شد که برای مردم ساده بود: از آنها خواسته شد در محل تشخیص دهند که آیا طیف گسترده ای از جملات از نظر دستوری در زبان مادری آنها به خوبی شکل گرفته است یا خیر. هم از انسان هایی که در این آزمایش شرکت کردند و هم از مدل های زبانی یک سوال بسیار ساده پرسیده شد: “آیا این جمله از نظر گرامری صحیح است؟”
نتایج نشان داد که انسانها به درستی پاسخ دادند، در حالی که مدلهای زبان بزرگ پاسخهای اشتباه بسیاری دادند. در واقع، مشخص شد که آنها یک استراتژی پیش فرض را برای پاسخ دادن به “بله” در بیشتر مواقع اتخاذ می کنند، صرف نظر از اینکه پاسخ صحیح است یا خیر.
ویتوریا دنتلا، محقق دپارتمان مطالعات انگلیسی و آلمانی که این مطالعه را رهبری میکند، توضیح میدهد: «نتیجه شگفتانگیز است، زیرا این سیستمها بر اساس آنچه از نظر گرامری درست است یا نه در یک زبان آموزش داده میشوند. ارزیابهای انسانی این مدلهای زبانی بزرگ را به صراحت در مورد گرامری بودن ساختارهایی که ممکن است با آنها مواجه شوند، آموزش میدهند.
با استفاده از یک فرآیند یادگیری تقویت شده توسط بازخورد انسان، به این مدلها نمونههایی از جملاتی داده میشود که از نظر گرامری به خوبی ساخته نشدهاند و سپس نسخه صحیح داده میشوند. این نوع آموزش بخش اساسی “آموزش” آنهاست. از طرفی در انسان اینطور نیست. او میگوید: «اگرچه افرادی که نوزاد را بزرگ میکنند ممکن است گهگاه نحوه صحبت کردن او را اصلاح کنند، اما در هیچ جامعه زبانی در سراسر جهان این کار را به طور مداوم انجام نمیدهند.
بنابراین، این مطالعه نشان می دهد که یک عدم تطابق مضاعف بین انسان و هوش مصنوعی وجود دارد. مردم به “شواهد منفی” – در مورد آنچه در زبان مورد صحبت از نظر گرامری صحیح نیست – دسترسی ندارند، در حالی که مدلهای زبانی بزرگ، از طریق بازخورد انسانی، به آن دسترسی دارند. اما با این وجود، مدلها نمیتوانند اشتباهات دستوری ناچیز را تشخیص دهند، در حالی که انسانها فورا و بدون زحمت میتوانند.
توسعه ابزارهای مفید و ایمن هوش مصنوعی میتواند بسیار مفید باشد، اما ما باید از کاستیهای آنها آگاه باشیم. از آنجایی که بیشتر برنامههای هوش مصنوعی به درک دستورات دادهشده به زبان طبیعی بستگی دارد، همانطور که در این مطالعه انجام دادیم، درک محدود آنها از گرامر تعیین میشود. Evelina Leivada، پروفسور تحقیقاتی ICREA از دپارتمان مطالعات کاتالان UAB، خاطرنشان میکند که این امر از اهمیت حیاتی برخوردار است.
دنتلا که معتقد است پذیرش این مدلهای زبانی به عنوان نظریههای زبان انسانی در مرحله کنونی توسعه آنها موجه نیست، نتیجهگیری میکند: «این نتایج نشان میدهد که ما باید به طور انتقادی در مورد اینکه آیا هوش مصنوعی واقعاً مهارتهای زبانی مشابه مهارتهای افراد را دارد یا خیر، تأمل کنیم.













