1 فوریه 2023 -توسط دانشگاه متروپولیتن اوزاکا
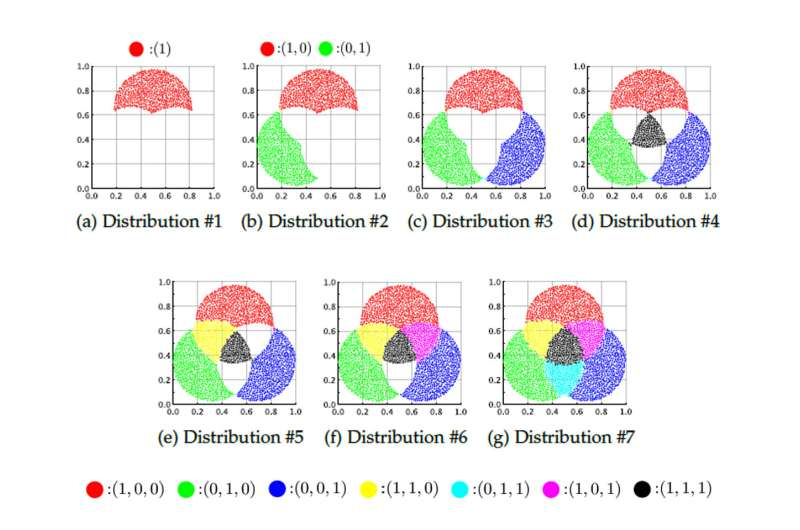
شکل نشان می دهد که چگونه سیستم ، اطلاعات جدید هر بار که یک توزیع داده وارد می شود، یاد می گیرد، در حالی که اطلاعات آموخته شده در گذشته را حفظ می کند. اعتبار: نائوکی ماسویاما، دانشگاه متروپولیتن اوزاکا
پیشرفت در فناوری اینترنت اشیا (IoT) این امکان را برای ما فراهم کرده است که به راحتی و به طور مداوم مقادیر زیادی از داده های متنوع را به دست آوریم. فناوری هوش مصنوعی به عنوان ابزاری برای استفاده از این کلان داده ها مورد توجه قرار گرفته است.
یادگیری ماشینی معمولی عمدتاً با مشکلات طبقهبندی تک برچسبی سروکار دارد که در آن دادهها و پدیدهها یا اشیاء مربوطه (اطلاعات برچسب) در یک رابطه یک به یک هستند. با این حال، در دنیای واقعی، داده ها و اطلاعات برچسب به ندرت رابطه یک به یک دارند.
بنابراین، در سالهای اخیر، توجه بر مسئله طبقهبندی چند برچسبی متمرکز شده است، که با دادههایی سروکار دارد که رابطه یک به چند بین دادهها و اطلاعات برچسب دارند. به عنوان مثال، یک عکس منظره ممکن است چندین برچسب برای عناصری مانند آسمان، کوه ها و ابرها داشته باشد. علاوه بر این، برای یادگیری کارآمد از داده های بزرگ که به طور مداوم به دست می آیند، توانایی یادگیری در طول زمان بدون از بین بردن چیزهایی که قبلاً آموخته شده اند نیز مورد نیاز است.
یک گروه تحقیقاتی به سرپرستی دانشیار پروفسور نائوکی ماسویاما و پروفسور یوسوکه نوجیما از دانشکده تحصیلات تکمیلی انفورماتیک دانشگاه متروپولیتن اوزاکا، روش جدیدی را توسعه دادهاند که عملکرد طبقهبندی دادهها را با چندین برچسب، با توانایی یادگیری مداوم با دادهها ترکیب میکند. آزمایشهای عددی روی مجموعه دادههای چند برچسبی در دنیای واقعی نشان داد که روش پیشنهادی از روشهای مرسوم بهتر عمل میکند.
سادگی این الگوریتم جدید، ابداع یک نسخه تکامل یافته را که می تواند با الگوریتم های دیگر ادغام شود، آسان می کند. از آنجایی که روش خوشهبندی اساسی دادهها را بر اساس شباهت بین ورودیهای داده گروهبندی میکند، انتظار میرود که ابزار مفیدی برای پیش پردازش مستمر کلان داده باشد.
علاوه بر این، اطلاعات برچسب اختصاص داده شده به هر خوشه به طور مداوم با استفاده از روشی مبتنی بر رویکرد بیزی آموخته می شود. با یادگیری داده ها و یادگیری اطلاعات برچسب مربوط به داده ها به طور جداگانه و مداوم، هم عملکرد طبقه بندی بالا و هم قابلیت یادگیری مستمر حاصل می شود.
پروفسور ماسویاما گفت: “ما معتقدیم که روش ما قادر به یادگیری مداوم از داده های چند برچسبی است و دارای قابلیت های مورد نیاز برای هوش مصنوعی در جامعه داده های بزرگ آینده است.”
نتایج تحقیق در IEEE Transactions on Pattern Analysis and Machine Intelligence در 19 دسامبر 2022 منتشر شد.












