5 مه 2022 – توسط آدام زوی، موسسه فناوری ماساچوست
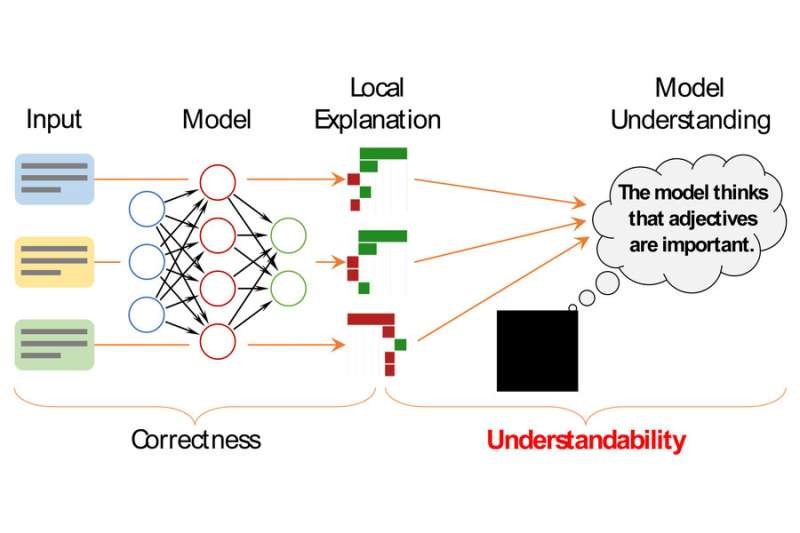
محققان از روشهای توضیح محلی برای درک نحوه تصمیمگیری مدلهای یادگیری ماشینی استفاده میکنند. حتي اگر اين توضيحات صحيح باشند، اگر انسان ها نتوانند منظور آنها را بفهمند، فايده اي ندارند. محققان MIT اکنون یک چارچوب ریاضی برای تعیین کمیت و ارزیابی قابل فهم بودن یک توضیح ایجاد کرده اند. اعتبار: موسسه فناوری ماساچوست
مدلهای مدرن یادگیری ماشینی، مانند شبکههای عصبی، اغلب به عنوان «جعبههای سیاه» شناخته میشوند، زیرا آنقدر پیچیده هستند که حتی محققانی که آنها را طراحی میکنند نمیتوانند به طور کامل بفهمند که چگونه پیشبینی میکنند.
برای ارائه برخی بینش ها، محققان از روشهای توضیحی استفاده میکنند که به دنبال توصیف تصمیمهای مدل فردی هستند. برای مثال، آنها ممکن است کلماتی را در یک نقد فیلم برجسته کنند که بر تصمیم مدل مبنی بر مثبت بودن نقد تأثیر گذاشته است.
اما این روشهای توضیحی هیچ فایدهای ندارند، اگر انسانها نتوانند به راحتی آنها را درک کنند یا حتی آنها را اشتباه درک کنند. بنابراین، محققان MIT یک چارچوب ریاضی برای تعیین کمیت و ارزیابی رسمی قابل فهم بودن توضیحات برای مدلهای یادگیری ماشینی ایجاد کردند. این می تواند به مشخص کردن بینش هایی در مورد رفتار مدل کمک کند که اگر محقق تنها تعداد انگشت شماری از توضیحات فردی را ارزیابی کند تا بتواند کل مدل را درک کند، ممکن است نادیده گرفته شود.
دانشجوی آزمایشگاه علوم کامپیوتر و هوش مصنوعی (CSAIL) و نویسنده اصلی مقاله ای که این چارچوب را ارائه می دهد، ییلون ژو، فارغالتحصیل مهندسی برق و علوم کامپیوتر میگوید: «با این چارچوب، ما میتوانیم نه تنها تصویر واضحی از آنچه در مورد مدل از این توضیحات محلی میدانیم، بلکه مهمتر از آن چیزهایی که در مورد آن نمیدانیم داشته باشیم..
نویسندگان همکار ژو عبارتند از مارکو تولیو ریبیرو، محقق ارشد مایکروسافت ریسرچ، و نویسنده ارشد جولی ش کینگ، استاد هوانوردی و فضانوردی و مدیر گروه رباتیک تعاملی در CSAIL. این تحقیق در کنفرانس بخش آمریکای شمالی انجمن زبانشناسی محاسباتی ارائه خواهد شد.
درک توضیحات محلی
یکی از راههای درک مدل یادگیری ماشینی، یافتن مدل دیگری است که از پیشبینیهای آن تقلید میکند اما از الگوهای استدلال شفاف استفاده میکند. با این حال، مدلهای شبکه عصبی اخیر آنقدر پیچیده هستند که این تکنیک معمولاً با شکست مواجه میشود. در عوض، محققان به استفاده از توضیحات محلی که بر ورودیهای فردی متمرکز است متوسل میشوند. اغلب، این توضیحات، کلمات موجود در متن را برجسته میکنند تا اهمیت آنها را برای یک پیشبینی انجامشده توسط مدل نشان دهند.
به طور ضمنی، مردم سپس این توضیحات محلی را به رفتار مدل کلی تعمیم می دهند. ممکن است کسی ببیند که یک روش توضیح محلی کلمات مثبت (مانند “به یاد ماندنی”، “بی عیب”، یا “جذاب کننده”) را به عنوان تاثیرگذارترین آنها در زمانی که مدل تصمیم گرفت که نقد فیلم دارای احساسات مثبت باشد، برجسته می کند. به گفته ژو، آنها احتمالاً فرض می کنند که همه کلمات مثبت نقش مثبتی در پیش بینی های یک مدل دارند، اما ممکن است همیشه اینطور نباشد.
محققان چارچوبی به نام ExSum خلاصه مختصر توضیحی ایجاد کردند که آن نوع ادعاها را به قوانینی تبدیل می کند که می توانند با استفاده از معیارهای سنجش کمی آزمایش شوند. ExSum یک قانون را بر روی کل مجموعه داده ارزیابی می کند، نه فقط نمونه واحدی که برای آن ساخته شده است.
با استفاده از یک رابط کاربری گرافیکی، یک فرد قوانینی را می نویسد که می توان آنها را تغییر داد، تنظیم کرد و ارزیابی کرد. به عنوان مثال، هنگام مطالعه مدلی که یاد میگیرد نقدهای فیلم را به مثبت یا منفی طبقهبندی میکند، ممکن است قاعدهای بنویسید که میگوید «کلمات نفی برجستگی منفی دارند» به این معنی که کلماتی مانند «نه» و «هیچ چیز» به احساسات نقدهای فیلم کمک می کند.
با استفاده از ExSum، کاربر می تواند ببیند که آیا این قانون با استفاده از سه معیار خاص: پوشش، اعتبار و وضوح ادامه دارد یا خیر. پوشش میزان کاربرد گسترده این قانون در کل مجموعه داده را اندازه گیری می کند. اعتبار درصدی از نمونههای منفرد را که با این قانون موافق هستند برجسته میکند. وضوح توضیح می دهد که این قانون چقدر دقیق است. یک قانون بسیار معتبر می تواند آنقدر عمومی باشد که برای درک مدل مفید نباشد.
فرضیات آزمایش
ژو میگوید اگر محققی به دنبال درک عمیقتری از نحوه رفتار مدلش باشد، میتواند از ExSum برای آزمایش مفروضات خاص استفاده کند.
اگر او مشکوک است که مدلش از نظر جنسیت تبعیض آمیز است، می تواند قوانینی ایجاد کند که بگوید ضمایر مذکر سهم مثبت و ضمایر مؤنث سهم منفی دارند. اگر این قوانین اعتبار بالایی داشته باشند، به این معنی است که در کل درست هستند و مدل احتمالاً مغرضانه است.
ExSum همچنین می تواند اطلاعات غیرمنتظره ای را در مورد رفتار یک مدل فاش کند. به عنوان مثال، هنگام ارزیابی طبقهبندی نقد فیلم، محققان از دریافت این نکته متعجب شدند که کلمات منفی نسبت به کلمات مثبت سهم بیشتری در تصمیمگیریهای مدل دارند. ژو توضیح میدهد که این میتواند به این دلیل باشد که نویسندگان نقد سعی میکنند هنگام نقد یک فیلم مؤدبانه و کمتر صریح رفتار کنند.
او گفت: “برای اینکه واقعاً درک خود را تأیید کنید، باید این ادعاها را در بسیاری از موارد بسیار دقیقتر ارزیابی کنید. این نوع درک در این سطح دقیق، تا آنجا که ما میدانیم، هرگز در آثار قبلی کشف نشده است.”
ریبیرو می افزاید: “رفتن از توضیحات محلی به درک جهانی یک شکاف بزرگ در ادبیات بود. ExSum اولین گام خوبی برای پر کردن این شکاف است.”
گسترش چارچوب
در آینده، ژو امیدوار است با بسط مفهوم قابل درک بودن به سایر معیارها و اشکال توضیحی، مانند توضیحات خلاف واقع (که نشان می دهد چگونه یک ورودی را برای تغییر پیش بینی مدل تغییر دهیم) این کار را توسعه دهد. در حال حاضر، آنها بر روی روشهای انتساب ویژگی تمرکز کردند، که ویژگیهای فردی را که یک مدل برای تصمیمگیری استفاده میکند (مانند کلمات در یک بررسی فیلم) توصیف میکند.
علاوه بر این، او میخواهد چارچوب و رابط کاربری را بیشتر تقویت کند تا مردم بتوانند قوانین را سریعتر ایجاد کنند. نوشتن قوانین میتواند به ساعتها مشارکت انسانی نیاز داشته باشد – و سطحی از مشارکت انسانی بسیار مهم است زیرا انسانها در نهایت باید بتوانند توضیحات را درک کنند – اما کمک هوش مصنوعی میتواند این فرآیند را سادهتر کند.
همانطور که او در مورد آینده ExSum فکر می کند، ژو امیدوار است که کار آنها نیاز به تغییر روش تفکر محققان در مورد توضیحات مدل یادگیری ماشین را برجسته کند.
“قبل از این کار، اگر توضیح محلی درستی داشته باشید، کارتان تمام شده است. شما به جام مقدس توضیح مدل خود دست یافته اید. ما این بعد اضافی را برای اطمینان از قابل فهم بودن این توضیحات پیشنهاد می کنیم. قابل درک بودن باید معیار دیگری برای ارزیابی باشد.