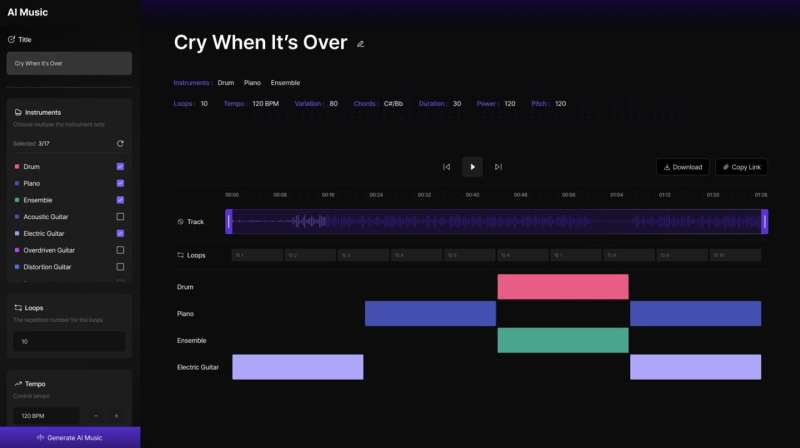
1 اکتبر 2024 – توسط Ingrid Fadelli، Tech Xplore-اسکرین شات از نسخه ی نمایشی سیستم تیم که رابط کاربری آن را نشان می دهد. اعتبار: هان و همکاران
هوش مصنوعی (AI) فرصت های جالب جدیدی را برای صنعت موسیقی باز کرده است، به عنوان مثال، امکان توسعه ابزارهایی را فراهم می کند که می توانند به طور خودکار آهنگ های موسیقی یا آهنگ های ساز خاص را تولید کنند. با این حال، بیشتر ابزارهای موجود برای استفاده ، برخلاف کاربران غیرمتخصص توسط نوازندگان، آهنگسازان و تولیدکنندگان موسیقی طراحی شدهاند.
محققان LG AI Research اخیراً یک سیستم تعاملی جدید ایجاد کرده اند که به هر کاربری اجازه می دهد به راحتی ایده های خود را به موسیقی ترجمه کند. این سیستم، که در مقاله منتشر شده در سرور preprint arXiv مشخص شده است، یک ترانسفورماتور اتورگرسیو فقط رمزگشا را که بر روی مجموعه داده های موسیقی آموزش دیده است، با یک رابط کاربری بصری ترکیب می کند.
سانگجون هان، جیوون هام و همکارانشان در مقاله خود نوشتند: “ما نمایش نسل موسیقی نمادین را با تمرکز بر ارائه موتیف های کوتاه موسیقایی که به عنوان موضوع اصلی روایت عمل می کنند، معرفی می کنیم.” برای نسل جدید، ما یک مدل اتورگرسیو را اتخاذ می کنیم که ابرداده های موسیقی را به عنوان ورودی می گیرد و 4 نوار از توالی های MIDI چند آهنگی تولید می کند.
مدل مبتنی بر ترانسفورماتور زیربنای سیستم تولید موسیقی نمادین تیم بر روی دو مجموعه داده موسیقی، یعنی مجموعه داده Lakh MIDI و مجموعه داده MetaMIDI آموزش داده شد. در مجموع، این مجموعه داده ها حاوی بیش از 400000 فایل MIDI (رابط دیجیتال آلات موسیقی) هستند که فایل های داده ای حاوی اطلاعات مختلف در مورد آهنگ های موسیقی (به عنوان مثال، نت های پخش شده، مدت زمان نت ها، سرعت پخش آنها) هستند.
برای آموزش مدل خود، تیم هر فایل MIDI را به یک فایل نمایش رویداد موسیقی (REMI) تبدیل کرد. این فرمت خاص، دادههای MIDI را در توکنهایی رمزگذاری میکند که نشاندهنده ویژگیهای مختلف موسیقی (مانند زیر و بم و سرعت) هستند. فایلهای REMI پویایی موسیقی را به شیوههایی به تصویر میکشند که برای آموزش مدلهای هوش مصنوعی برای تولید موسیقی مناسب است.
محققان نوشتند: «در طول آموزش، ما بهطور تصادفی توکنهایی را از ابردادههای موسیقی حذف میکنیم تا کنترل انعطافپذیر را تضمین کنیم». “این آزادی را برای کاربران فراهم می کند تا انواع ورودی را با حفظ عملکرد تولیدی انتخاب کنند و انعطاف پذیری بیشتری را در ترکیب موسیقی فراهم می کند.”
هان، هام و همکارانشان علاوه بر توسعه مدل مبتنی بر ترانسفورماتور خود برای تولید موسیقی نمادین، یک رابط کاربری ساده ایجاد کردند که هم برای کاربران متخصص و هم برای کاربران غیرمتخصص قابل دسترسی است. این رابط در حال حاضر از یک نوار کناری و یک پانل تعاملی مرکزی تشکیل شده است.
در نوار کناری، کاربران میتوانند جنبههایی از موسیقی را که میخواهند مدل تولید کند، مشخص کنند، مانند سازهایی که باید پخش شوند و سرعت آهنگ. پس از اینکه مدل آهنگی را تولید کرد، میتوانند آهنگ را در پانل مرکزی ویرایش کنند، برای مثال، با حذف/افزودن سازها یا تنظیم زمان شروع پخش موسیقی.
هان، هام و همکارانشان نوشتند: «ما اثربخشی استراتژی را از طریق آزمایشها از نظر ظرفیت مدل، وفاداری موسیقی، تنوع و کنترلپذیری تأیید میکنیم. “علاوه بر این، ما مدل را مقیاسبندی میکنیم و آن را با سایر مدلهای تولید موسیقی از طریق یک آزمون ذهنی مقایسه میکنیم. نتایج ما نشان دهنده برتری آن در کنترل و کیفیت موسیقی است.”
محققان دریافتند که مدل آنها به طور قابل توجهی عملکرد خوبی دارد و می تواند به طور قابل اعتماد حداکثر 4 نوار موسیقی بر اساس مشخصات کاربر تولید کند. در مطالعات آتی خود، آنها میتوانند سیستم خود را با افزایش مدت زمان آهنگهایی که مدلشان میتواند ایجاد کند، گسترش بیشتر مشخصاتی که کاربران میتوانند ارائه دهند، و بهبود بیشتر رابط کاربری سیستم، بهبود بخشند.
محققان نوشتند: «مدل ما که برای تولید 4 نوار موسیقی با کنترل جهانی آموزش داده شده است، محدودیتهایی در افزایش طول موسیقی و کنترل عناصر محلی در سطح نوار دارد. با این حال، تلاشهای ما در تولید تمهای موسیقی با کیفیت بالا که میتوانند به عنوان حلقه استفاده شوند، اهمیت دارد.»













