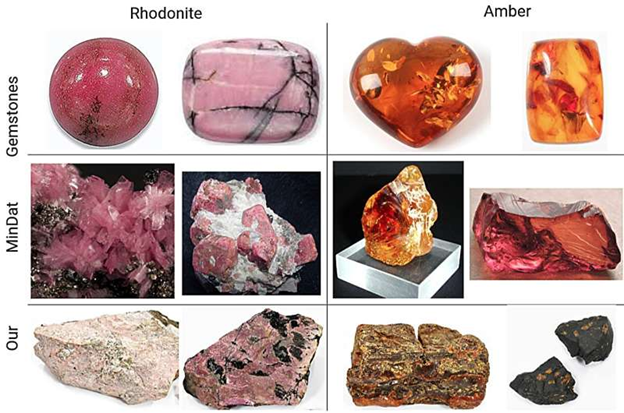
25 اوت 2023 -توسط آرتور کادورین، نمونه هایی از عکس های معدنی از مجموعه داده های مختلف. اعتبار: آرتور کادورین
شناسایی مواد معدنی یک مشکل پیچیده و زمان بر برای زمین شناسان است که اغلب از 30 دقیقه تا چند روز در هر نمونه زمان می برد. پیچیدگی بیشتر وضعیت این واقعیت است که بخش کافی از مواد معدنی به اندازه کافی مورد بررسی قرار نگرفته است و تنها چند صد مورد از 6000 ماده معدنی شناسایی شده کنونی را به ما میگذارد.
تشخیص بصری کانی ها و سنگ ها یک عمل گسترده در زمین شناسی است، زیرا بسیار ارزان تر و سریعتر از روش های دیگر مانند طیف سنجی و تجزیه و تحلیل شیمیایی است. با این حال، در مقایسه با روش های گران تر، زمان بر و دقت کمتری دارد. حتی کانی شناسان باتجربه می توانند هنگام کار با یک ماده کمیاب یا نمونه با کیفیت پایین اشتباه کنند. گنجاندن هوش ماشینی در این فرآیند می تواند به شناسایی خطا کمک کند و زمان صرف شده برای کارهای معمول توسط متخصصان را کاهش دهد.
علیرغم تحقیقات مداوم در این زمینه، فقدان معیار مشخصی برای تجزیه و تحلیل تصویر معدنی در ادبیات علمی وجود دارد. برای رفع این شکاف، مؤسسه تحقیقاتی هوش مصنوعی با همکاری Sber AI و دانشگاه دولتی لومونوسوف مسکو، یک مجموعه داده معیار برای مدلهای بینایی کامپیوتری با تمرکز بر تشخیص مواد معدنی ایجاد کرده است.
ما مجموعه داده را MineralImage5k نامیدیم. این بر اساس مجموعه موزه کانی شناسی Fersman است و شامل 44 هزار نمونه است. در حالی که کوچکتر از مجموعه داده Mindat است، MineralImage5k همگنی بیشتری از شرایط عکس ارائه می دهد و از نمونه های پردازش نشده تشکیل شده است که بسیار شبیه به کانی های طبیعی است.
مجموعه داده MineralImage5k به سه زیرمجموعه با پیچیدگی های مختلف تقسیم می شود که محققان را در طبقه بندی مواد معدنی، تقسیم بندی و تخمین اندازه به چالش می کشد. ساده ترین کار طبقه بندی ارائه شده در معیار شامل ده گونه معدنی با حداقل 462 نمونه در هر گونه است. مشکل ترین مشکل طبقه بندی مواد معدنی به کلاس های 5K با تنها یک تصویر در هر کلاس است.
یکی از مشکلاتی که هوش مصنوعی ممکن است هنگام کار با عکسهای یک کانی با آن مواجه شود این است که کدام بخش از سنگ ارائه شده یک کانی واقعی مورد علاقه است. برای رفع این مشکل، مجموعه جداگانهای از حدود 100 تصویر را با برچسبهای اضافی و وظیفه تقسیمبندی علاوه بر طبقهبندی به اشتراک میگذاریم. ادغام وظیفه تقسیمبندی در جریان طبقهبندی ممکن است بینش بیشتری در مواردی که مدل اشتباه میکند و تعداد چنین موقعیتهایی را کاهش میدهد، ارائه دهد.
فراتر از طبقه بندی و تقسیم بندی، ما تخمین اندازه کانی صفر شات را مطالعه می کنیم. تخمین خودکار اندازه نمونه می تواند برای روش های نگهداری نمونه های موزه بسیار مفید باشد. با داشتن این دادهها برای همه نمونهها، میتوانیم سیستم ذخیرهسازی بهینه را برنامهریزی کنیم و جعبههایی را با اندازه مناسب در مقدار مناسب خریداری یا تولید کنیم. بنابراین، ما بیش از 18 هزار نمونه برچسبدار برای کار رگرسیون در معیار خود ارائه میکنیم.
برای نشان دادن اثربخشی معیار، ما یک مدل زبان بینایی را که از قبل بر روی دادههای دامنه عمومی آموزش داده شده بود، ارزیابی کردیم. ما متوجه شدیم که تنظیم دقیق مدل در مجموعه داده های دامنه خاص مانند MineralImage5k ممکن است به طور قابل توجهی دقت آن را بهبود بخشد. ما همچنین پتانسیل امیدوارکننده ارزیابی مجموعه دادههای متقابل را برای ارزیابی مدلهای تشخیص معدنی برجسته میکنیم.
تحقیق ما در مجله Computers & Geosciences منتشر شده است. ما خوشحالیم که به استفاده از مجموعه داده و معیار کمک می کنیم و از همه محققان علاقه مند دعوت می کنیم تا ایده های خود را برای مفیدتر کردن آن برای جامعه به اشتراک بگذارند.
این داستان بخشی از Science X Dialog است، جایی که محققان می توانند یافته های مقالات تحقیقاتی منتشر شده خود را گزارش کنند. برای اطلاعات در مورد ScienceX Dialog و نحوه مشارکت از این صفحه دیدن کنید.