8 نوامبر 2024 -توسط محاسبات هوشمند
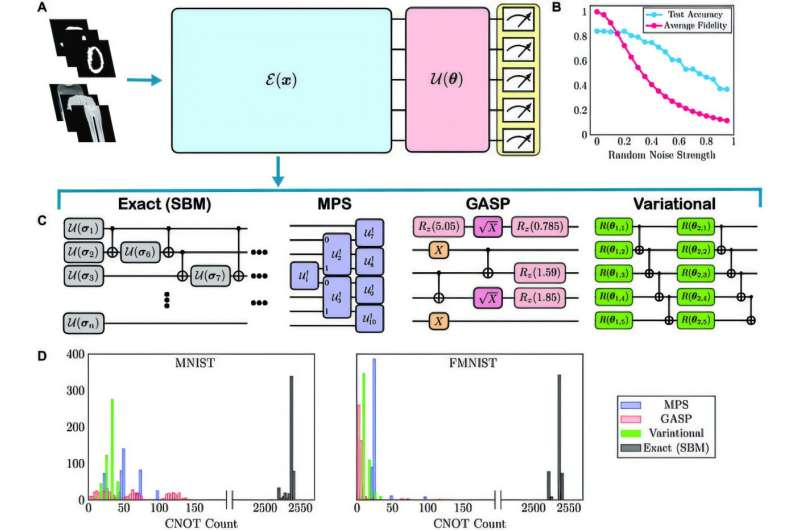
این نمودار نشان میدهد که چگونه این تیم پیچیدگی مدار کوانتومی را در یادگیری ماشین با استفاده از سه روش رمزگذاری – الگوریتمهای حالت محصول متغیر، ژنتیکی و ماتریسی کاهش میدهد. همانطور که توسط هیستوگرام کاهش تعداد گیت های CNOT نشان داده شده است، همه روش ها به طور قابل توجهی عمق مدار را کاهش می دهند و در عین حال دقت را حفظ می کنند. اعتبار: محاسبات هوشمند (2024).
مطالعه اخیر محققان CSIRO و دانشگاه ملبورن در یادگیری ماشین کوانتومی پیشرفت کرده است، زمینه ای که هدف آن دستیابی به مزیت کوانتومی برای پیشی گرفتن از یادگیری ماشین کلاسیک است.
کار آنها نشان میدهد که مدارهای کوانتومی برای رمزگذاری دادهها در یادگیری ماشین کوانتومی میتوانند تا حد زیادی بدون به خطر انداختن دقت یا استحکام سادهسازی شوند. این تحقیق در 12 سپتامبر در محاسبات هوشمند منتشر شد.
نتایج این تیم که از طریق شبیهسازی و آزمایش بر روی دستگاههای کوانتومی IBM تأیید شده است، نشان میدهد که روشهای رمزگذاری نوآورانه آنها عمق مدار را در مقایسه با روشهای سنتی به طور متوسط ۱۰۰ برابر کاهش میدهد و در عین حال به دقت طبقهبندی مشابهی دست مییابد. این یافته ها یک مسیر جدید هیجان انگیز برای کاربرد عملی یادگیری ماشین کوانتومی در دستگاه های کوانتومی فعلی ارائه می دهد.
با نگاهی به آینده، این تیم قصد دارد این مدلها را برای مجموعه دادههای بزرگتر و پیچیدهتر مقیاسبندی کند و بهینهسازیهای بیشتر در کدگذاری حالت کوانتومی و طراحی معماری یادگیری ماشین کوانتومی را بررسی کند.
یکی از موانع کلیدی یادگیری ماشین کوانتومی کارآمد، رمزگذاری دادههای کلاسیک در حالتهای کوانتومی است، یک کار محاسباتی چالش برانگیز که نیازمند مدارهای عمیقاً درهمتنیده است. برای غلبه بر این موضوع، تیم سه روش رمزگذاری را معرفی کرد که وضعیت کوانتومی داده ها را با استفاده از مدارهای بسیار کم عمق تقریبی می کند.
این روشها – حالت محصول ماتریسی، الگوریتمهای ژنتیکی و تنوع – دقت طبقهبندی را در مجموعه داده تصویر MNIST و دو روش دیگر حفظ کردند و در عین حال انعطافپذیری را در برابر دستکاری دادههای ضد ونقیض افزایش دادند.هر روش به طور منحصربهفرد حالت کوانتومی را کدگذاری دادههای کلاسیک برای فعال کردن آمادهسازی حالت کارآمد تقریب میکند:
کدگذاری حالت محصول ماتریسی: این رویکرد از شبکه های تانسور برای ایجاد حالت های کوانتومی استفاده می کند که می توانند به طور متوالی از هم جدا شوند. این ساختار به حالت های کوانتومی با درهم تنیدگی کم اجازه می دهد تا با تعداد کمی از دروازه های Controlled-NOT یا CNOT آماده شوند که پیچیدگی را بیشتر کاهش می دهد.
الگوریتم ژنتیک برای آمادهسازی حالت: این رویکرد با الهام از فرآیندهای تکاملی، فرآیند آمادهسازی حالت را با ایجاد پیکربندیهای مدار مختلف، انتخاب کارآمدترین و به حداقل رساندن تعداد گیتهای CNOT بهینه میکند، بنابراین مدارها را در برابر نویز مقاومتر میکند.
کدگذاری متغیر: این روش از پارامترهای قابل آموزش در ساختار مدار لایه ای استفاده می کند و به حالت های کوانتومی اجازه می دهد تا در لایه های کمتری به دقت هدف برسند. این امر نیاز به عملیات درهم تنیدگی گسترده را کاهش می دهد و معمولاً هزینه های محاسباتی را کاهش می دهد.
این کار با اهداف گستردهتری در یادگیری ماشین کوانتومی برای ساخت مدلهای کوانتومی کارآمد و قابل اعتماد برای حوزههایی مانند تشخیص تصویر، امنیت سایبری و تجزیه و تحلیل دادههای پیچیده همسو است. کاهش عمق مدار برای دستیابی به یادگیری ماشین کوانتومی عملی در دستگاههای فعلی، که اغلب توسط وفاداری گیت و تعداد کیوبیت محدود میشوند، حیاتی است.
افزایش استحکام این مدلها در برابر حملات خصمانه، فرصتهای جدیدی را برای کاربردهای یادگیری ماشین کوانتومی امن در بخشهایی که انعطافپذیری در برابر دستکاری ضروری است، باز میکند.