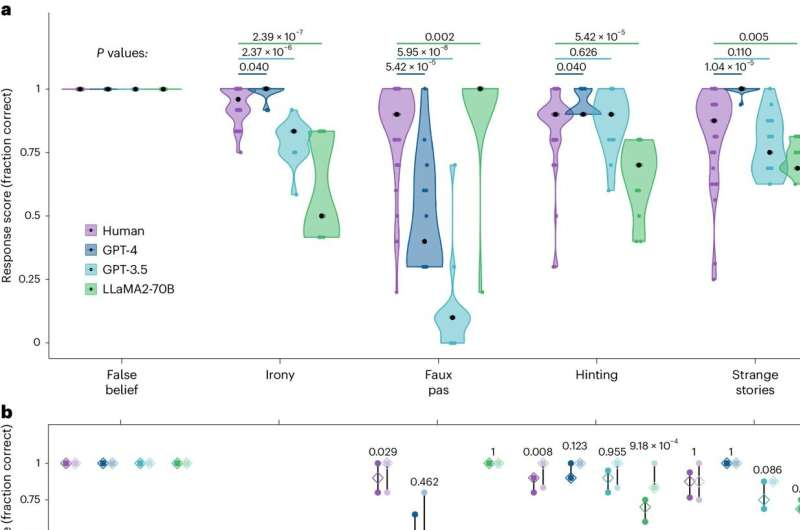
گزارش 21 مه 2024 -توسط باب یرکا، Tech Xplore-عملکرد انسان (بنفش)، GPT-4 آبی تیره، GPT-3.5 (آبی روشن) و LLaMA2-70B (سبز) بر روی تست باتری تئوری ذهن. الف، آیتمهای آزمون اصلی برای هر آزمون که توزیع نمرات آزمون را برای هر جلسه و شرکتکنندگان نشان میدهد. ب، محدوده بین ربعی میانگین نمرات در موارد منتشر شده اصلی (رنگ های تیره) و موارد جدید (رنگ های کم رنگ) در هر آزمون. اعتبار: طبیعت رفتار انسانی
یک تیم بینالمللی متشکل از روانشناسان و عصببیولوژیستها از طریق آزمایش دریافتند که دو نوع LLM میتوانند در آزمونهای تئوری ذهن با انسانها برابر یا بهتر عمل کنند. در مطالعه خود که در مجله Nature Human Behavior گزارش شده است، این گروه تستهای تئوری ذهن را برای داوطلبان اجرا کردند و میانگین نتایج را با نتایج دو نوع LLM مقایسه کردند.
در چند سال گذشته، مدلهای زبان بزرگ (LLM) مانند ChatGPT به حدی بهبود یافتهاند که اکنون برای استفاده عمومی در دسترس عموم قرار گرفتهاند. آنها همچنین به طور پیوسته در توانایی های خود رشد کرده اند. یکی از تواناییهای جدید، استنتاج خلق و خوی معانی پنهان یا وضعیت ذهنی یک کاربر انسانی است.
در این مطالعه جدید، تیم تحقیقاتی به این فکر افتاد که آیا تواناییهای LLM به حدی رسیده است که بتوانند وظایف تئوری ذهن را همتراز انسانها انجام دهند.
وظایف تئوری ذهن توسط روانشناسان برای اندازه گیری وضعیت ذهنی و/یا احساسی یک فرد در طول تعاملات اجتماعی طراحی شده است. تحقیقات قبلی نشان داده است که انسانها از نشانههای مختلفی برای نشان دادن وضعیت ذهنی خود به دیگران استفاده میکنند، با هدف برقراری ارتباط اطلاعات بدون اینکه مشخص باشند.
تحقیقات قبلی همچنین نشان داده است که انسان ها در دریافت چنین نشانه هایی برتری دارند، اما سایر حیوانات اینطور نیستند. بسیاری از افراد در این زمینه قبول کردن چنین آزمایشاتی را برای رایانه غیرممکن می دانند. تیم تحقیقاتی چندین LLM را آزمایش کردند تا ببینند که چقدر با جمعیتی از انسانها که آزمایشهای مشابه انجام میدهند، مقایسه میشوند.
محققان دادههای 1907 داوطلب را که تستهای تئوری استاندارد ذهن را انجام داده بودند، تجزیه و تحلیل کردند و نتایج را با نتایج چندین LLM مانند Llama 2-70b و GPT-4 مقایسه کردند. هر دو گروه به پنج نوع سؤال پاسخ دادند که هر کدام برای سنجش مواردی مانند خطای تقلبی، کنایه یا حقیقت یک جمله طراحی شده بودند. همچنین از هر کدام خواسته شد تا به سؤالات «باور نادرست» که اغلب برای کودکان انجام می شود، پاسخ دهند.
محققان دریافتند که LLM ها اغلب با عملکرد انسان برابری می کنند و گاهی اوقات بهتر عمل می کنند. به طور دقیق تر، آنها دریافتند که GPT-4 در پنج نوع اصلی از وظایف، بهترین بود، در حالی که امتیازات Llama-2 بسیار بدتر از سایر انواع LLM یا انسان بود، در برخی موارد، اما در برخی از سوالات از انواع دیگر بسیار بهتر بود.
به گفته محققان، این آزمایش نشان میدهد که LLMها در حال حاضر میتوانند در تستهای تئوری ذهن عملکردی مشابه با انسانها داشته باشند، اگرچه آنها نشان نمیدهند که چنین مدلهایی به اندازه انسانها باهوشتر یا باهوشتر یا به طور کلی بصریتر هستند.













