13 مارس 2023 – توسط Complexity Science Hub Vienna
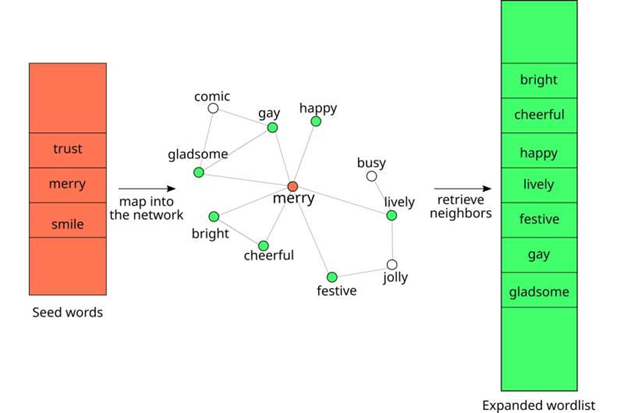
فهرست کوتاهی از کلمات اولیه (قرمز، در سمت چپ) با نگاشت کلمات بذر بر روی یک شبکه colexification و بازیابی گرههای همسایه، به فهرست کلمات طولانیتر (سبز، در سمت راست) گسترش مییابد. اعتبار Complexity Science Hub
فهرستهای واژهها اساس تحقیقات بسیاری در زمینههای مختلف است. محققان در Complexity Science Hub اکنون الگوریتمی را توسعه داده اند که می تواند در زبان های مختلف اعمال شود و می تواند لیست کلمات را به طور قابل توجهی بهتر از دیگران گسترش دهد.
بسیاری از پروژه ها نه تنها در شرکت ها که نقشه های ذهنی ایجاد می شوند، بلکه در تمام زمینه های تحقیقاتی با ایجاد فهرست کلمات شروع می شوند. تصور کنید می خواهید با تجزیه و تحلیل پست های توییتر متوجه شوید که در چه روزهایی مردم روحیه خوبی دارند. فقط جستجوی کلمه “شاد” کافی نیست.
در عوض، باید از الگوریتمی استفاده کنید که تمام توییتهایی را که نشان میدهند کسی خوشحال است را شناسایی میکند. آنا دی ناتال، محقق مرکز علوم پیچیدگی در وین، توضیح میدهد: «پس اولین قدم ایجاد فهرستی از تمام کلماتی است که دقیقاً این را نشان میدهند. اما چگونه میتوان دقیقترین و کاملترین فهرست کلمات ممکن را به دست آورد؟
مشکلی که خیلی ها را نگران کرده است
این مشکل گسترده نه تنها به پژوهشگرانی مربوط می شود که می خواهند بدانند اظهارات سیاستمداران چگونه توسط مردم دریافت می شود. شرکتها نیز میخواهند از طریق تحلیل احساسات متوجه شوند که محصولاتشان چگونه درک میشود.
برای بهبود شرایط، Di Natale اکنون یک روش جدید به نام LEXpander ایجاد کرده است که از الگوریتم های قبلی در دو زبان مختلف – آلمانی و انگلیسی – بهتر عمل می کند. علاوه بر این، برای اولین بار، او راهی را ایجاد کرده است که از طریق آن امکان مقایسه ابزارهای مختلف وجود دارد.
عملکرد بهبود یافته است
در مقایسه با چهار الگوریتم دیگر برای گسترش فهرست کلمات WordNet، Empath 2.0، FastText و GloVe، LEXpander به طور قابل توجهی بهتر عمل کرد، به خصوص در زبان آلمانی. به عنوان مثال، محققان دریافتند که LEXpander 43٪ از کلمات را درست هنگام گسترش فهرست کلمات انگلیسی برای معنای مثبت حدس میزند. یک مدل محبوب موجود، FastText، در مقایسه، تنها در 28٪ مواقع درست است.
استقلال از خود زبان
دلیل آن این است که این ابزار به طور مستقل از زبان کار می کند. این مبتنی بر یک زبان نیست، بلکه بر اساس یک شبکه به اصطلاح colexification است. این مفهوم زبانی شناخته شده بر روی همنام ها و چندمعنایی ها قرار دارد، کلمات واحدی که دو یا چند معنای متمایز دارند. به عنوان مثال: واژه یونانی باستان φάρμακον (pharmacon) می تواند به معنای دارو یا سم باشد. اینها دو چیز متفاوت هستند، اما از نظر موضوعی نزدیک هستند. اما موارد دیگری نیز وجود دارند که پیوند خویشاوندی را پیشنهاد نمی کنند – مانند “بانک” به عنوان یک موسسه مالی یا زمین در کنار رودخانه.
دی ناتال می گوید: “اگر آنها را در بسیاری از زبان ها جمع آوری کنید – و در اینجا ما حدود 19 زبان مختلف را تجزیه و تحلیل کردیم – می توانید ارتباط بین آنها را ببینید.” این شبکه زمانی شکل میگیرد که این ترکیببندیها در چندین زبان در میان خانوادههای زبانی مختلف رخ میدهند و ارتباطاتی ایجاد میکنند.
این استقلال از خود زبان به LEXpander اجازه می دهد تا در زبان های مختلف به نتایج بهتری دست یابد. “روش های زیادی برای انگلیسی توسعه داده شده است. آنها بسیار خوب و سریع کار می کنند و همه از آنها استفاده می کنند. تلاش برای اعمال آنها در زبان های دیگر کار می کند، اما نه به آن خوبی که اگر شما شروع به توسعه روشی برای آلمانی یا ایتالیایی کرده باشید.”
برای موضوعات جدید مانند COVID مهم است
برای بسیاری از موضوعات از قبل فهرست کلمات خوبی وجود دارد. اما برای موضوعات جدید – مانند کووید – باید موضوعات جدیدی ایجاد شود. تا پیش از این، معمولاً در زمان طوفان فکری بین همکاران، با دست ایجاد می شدند و از ابزارهای متعددی برای کمک استفاده می شد. اما تا به حال هیچ راهی برای مقایسه آنها وجود نداشت.
Anna Di Natale و تیمش اکنون این امکان را ایجاد کرده اند و همچنین ابزار جدیدی ساخته اند که عملکرد بهتری نسبت به سایرین دارد. این امر می تواند سنگ بنای مهمی برای بسیاری از پروژه های تحقیقاتی آینده در زمینه های مختلف باشد.